corrections acoustiques hifi
ŕ l'égaliseur numérique
Behringer DEQ2496
Vahé Zartarian
janvier 2010, complété novembre 2010
corrections acoustiques hifiŕ l'égaliseur numériqueBehringer DEQ2496Vahé Zartarianjanvier 2010, complété novembre 2010 |
Autres pages consacrées ŕ la musique:
science et ésotérisme
J’ai toujours trouvé paradoxal le
monde de la hifi, d’autant plus paradoxal que l’on monte en gamme : d’un
côté les technologies les plus pointues pour parfaire le traitement
des signaux ; de l’autre une foule de gadgets qui relčvent parfois
carrément de l’ésotérisme et de l’autosuggestion. C’est
que les systčmes d’écoute conçus en chambres sourdes pour
ętre parfaits acoustiquement parlant procure souvent ŕ l’auditeur,
une fois installés dans son salon de musique, de telles insatisfactions
voire désagréments qu’il fait ce qu’il peut pour retrouver un
son satisfaisant et justifier ŕ ses propres yeux son investissement.
Cela passe :
- soit par une égalisation déguisée
via des câbles, des supports, des cavités résonantes, etc.,
forcément inadéquate puisque rien n’est maîtrisé ;
- soit par un rejet de la technologie et un retour
aux valeurs ‘sűres’, comme le vinyle et le tube ; autrement dit on
préfčre payer (souvent trčs cher) des appareils qui produisent
des distorsions colossales et on est obligé de se justifier en qualifiant
lesdites distorsions de ‘musicales’ !
Bien sűr on a tous les droits, et si les résultats
ŕ l’écoute sont satisfaisants, pourquoi pas. Mais ne qualifions
plus ça de haute fidélité !
problčmes
Concrčtement, l’audiophile est principalement
confronté ŕ deux types de problčmes :
1. du côté du grave, soit il n’y
en a pas du tout, soit il est envahissant ;
2. la fatigue auditive.
Le premier relčve le plus souvent de l’acoustique
pure : mauvais placement des enceintes et phénomčnes de résonances
(męme si dans certains cas la disparition du grave peut ętre due
ŕ une écoute ŕ un niveau trop bas sans correction loudness :
j’y reviendrai).
Le second relčve de la psychoacoustique, principalement :
- l’accumulation d’harmoniques dans la zone de
sensibilité maximale de l’oreille ;
- des déséquilibres du spectre,
combinaison entre la réponse fréquentielle du couple sono-salle
et de la courbe de sensibilité de l’oreille ŕ un niveau d’écoute
donné ; ce déséquilibre oblige soit ŕ ‘tendre’
l’oreille inconsciemment pour retrouver des informations enfouies (de męme
que dans une salle bruyante l’on tend l’oreille pour suivre une conversation
particuličre), soit ŕ augmenter le volume pour les faire ressortir
mais au prix d’une accentuation des déséquilibres puisque toutes
les autres fréquences sont aussi augmentées ; dans tous les
cas cela se traduit par de la fatigue auditive.
solutions
Que ne s’est-on attaquer directement ŕ
ces problčmes plutôt que recourir ŕ des distorsions musicales
ou des gadgets ésotériques ? Je vois au moins deux raisons.
La premičre est la méconnaissance. Les
concepteurs, s’ils sont indéniablement compétents en acoustique
et traitement du signal, semblent souvent ignorer tout de la psychoacoustique.
Quant aux auditeurs-mélomanes-audiophiles, ils ne connaissent en général
ni l’une ni l’autre. Tous disent se fier ŕ leurs oreilles. Certes. Mais
comment obtenir des résultats valables et surtout durables si l’on ne
sait pas comment elles fonctionnent ? savoir, par exemple, que leur sensibilité
varie avec le niveau, que l’attente influence l’écoute (remarquons l’absence
quasi totale de tests d’écoutes en aveugle dans les comparatifs qui fleurissent
dans les magazines)…
La seconde raison qui a empęché de s’attaquer
directement ŕ ces problčmes est l’absence d’outils pour réaliser
de telles corrections. Quoique ! En fait il en existe, et depuis longtemps,
mais pas dans le domaine de la hifi, dans celui de la sonorisation et de l’enregistrement :
les égaliseurs. Domaines pourtant connexes mais qui ŕ ma connaissance
n’ont jamais bien communiqué. Aucun nom ne me vient de constructeur travaillant
dans ces différents domaines !
Il y a trois types d’égaliseurs que l’on peut utiliser en hifi entre une source et le préampli :
1. les égaliseurs graphiques
analogiques classiques 2x31 bandes
Ils peuvent apporter un réel confort d’écoute
(j’ai testé sur mon systčme un Behringer DEQ1024) en atténuant
les résonances, corrigeant les déséquilibre spectraux,
particuličrement dans la zone cruciale de sensibilité maximale
de l’oreille, et effectuant des corrections loudness. Ils présentent
toutefois quelques faiblesses qui, selon moi, les réservent ŕ
des chaînes hifi premiers prix, c’est-ŕ-dire ne se caractérisant
pas par une transparence trčs poussée ni une descente abyssale
dans l’extręme grave :
- une perte de transparence qui, męme si
elle est légčre, est parfaitement audible sur un systčme
de qualité (due semble-t-il ŕ des phénomčnes de
distorsion de phase) ;
- une précision insuffisante du réglage
des fréquences (les fréquences sautent par tiers d’octave contre
1/60 d’octave sur un paramétrique ; les bandes ont une largeur d’un
tiers d’octave alors qu’elle est réglable de 1/10 ŕ 1 voire plus
sur un paramétrique) ; cela rend difficile une correction des résonances
et un réglage parfait du grave.
2. les égaliseurs paramétriques
analogiques
De tels appareils sont plus rares, réservés
en général au mastering des enregistrements. Ils n’induisent pas
de distorsions de phase et permettent un réglage trčs précis
des fréquences des filtres et de leur largeur. Le hic est qu’ils sont
trčs chers. Sans compter que le nombre de filtres est limité (3
ŕ 5 en général), ce qui est trčs insuffisant pour
corriger tous les problčmes acoustiques.
3. les égaliseurs numériques
Conçus pour le mastering et/ou la gestion de
systčmes de diffusion. On en trouve chez TC-electronic (modčles
finalizer et EQ-station), DBX (drive-rack), Behringer (DEQ2496).
Il s’agit en fait de calculateurs dédiés au traitement du signal.
Ils sont trčs transparents car travaillant en 24bits-96kHz (contre 16bits-44.1kHz
pour le CD). Comme les calculateurs aujourd’hui sont trčs puissants,
et comme une fois un signal numérisé on peut procéder dessus
ŕ toutes les opérations qu’on veut sans introduire de distorsions,
ces appareils permettent effectivement de tout faire. En particulier ils combinent
égaliseur graphique 2x31 bandes et égaliseur paramétrique
2x10 bandes. L’idéal donc en hifi pour procéder ŕ toutes
les corrections qu’on veut.
Sauf qu’ils sont ou bien trčs chers (plusieurs
milliers d’euros) ou bien pas au niveau des exigences d’un audiophile. Le DEQ2496
(www.behringer.com),
tout en étant trčs recommandable en l’état ŕ moins
de 300€, pęche tout de męme par la qualité insuffisante de
son alimentation et de ses circuits d’entrées/sorties analogiques (il
dispose aussi d’entrées/sorties numériques mais je ne peux m’en
servir dans ma configuration). Tout problčme ayant une solution, plusieurs
sociétés vendent des DEQ2496 modifiés, qui en font au passage
de véritables DAC audiophiles. Mon choix s’est porté sur un DEQ
modifié par Simon Ashton (http://www.audiosmile.co.uk).
543Ł, soit 628€ au taux de change ŕ la date de mon
achat (05/01/2010), ne sont vraiment pas grand chose quand on voit tout ce qu’on
peut faire avec, quand on écoute les résultats (faible bruit,
grande transparence, corrections acoustiques et psychoacoustiques efficaces),
et qu’on compare aux prix des gadgets ŕ l’utilité plus que douteuse.
Pour ceux qui y trouveraient ŕ redire, considérant que ce n’est
pas assez cher ou pas assez audiophile, il faut savoir qu’y a de vraies solutions
audiophiles, évidemment dans une toute autre gamme de prix : par
exemple les produits Tact (www.tactlab.com)
ou Lyngdorf (www.lyngdorf.com).
Il n’en sera pas question ici.
sommaire
Entre les imperfections de l’ampli, celles
des enceintes, celles de la salle, et les problčmes issus de leur couplage,
nulle surprise si la courbe de réponse de l’ensemble est loin d’ętre
linéaire. Cela signifie que ce qui est diffusé n’est pas conforme
ŕ ce qui a été enregistré. Ajouté le fait
que la perception des différentes fréquences change selon le niveau
d’écoute, et l’on en arrive ŕ ceci : ce qui est entendu n’est
pas conforme au signal source.
Une correction acoustique a pour but de rendre la
réponse globale du systčme salle+sono+auditeur la plus fidčle
possible. Il faut tout de męme ętre lucide : un égaliseur,
aussi sophistiqué et de bonne qualité soit-il, ne saurait résoudre
tous les problčmes. Il n’est qu’un facteur parmi d’autres, en particulier :
la géométrie de la salle, les matériaux qui la constituent
et qui la recouvrent, les objets qui l’occupent, la position des enceintes,
la place d’écoute. Il faut commencer par agir sur tout ça (cf.
http://www.lafontaudio.com
). Si on le peut, et sachant que ça va corriger certains problčmes
(notamment les résonances et le niveau des graves) mais pas tous (pas
ceux qui relčvent de la psychoacoustique). Et il arrive qu’on ne puisse
pas. C’est mon cas ŕ Chaudon : parce que la pičce est petite
et qu’elle sert aussi de passage, je ne peux pas agir sur grand chose :
ni sur la géométrie, ni sur les meubles, ni sur la position d’écoute,
quant ŕ la position des enceintes elle offre une faible marge de manœuvre !
Dans ces conditions mon seul recours est l’égalisation.
La suite de ce document comprend trois parties :
- la premičre est consacrée ŕ quelques rappels d’acoustique et de psychoacoustique pour comprendre ce qu’il y a ŕ faire
- la deuxičme examine ce qui peut ętre fait avec un DEQ2496 et comment le faire
- la troisičme est l’application de tout ça ŕ mon actuel salon de musique
Toute cavité résonante est le théâtre d’ondes stationnaires. C’est grâce ŕ ça que les instruments de musique émettent des notes ŕ des hauteurs précises. En quelque sorte se produit un filtrage : toutes les fréquences qui ne sont pas accordées ŕ la cavité s’atténuent trčs vite et donc s’éliminent ; sont au contraire amplifiées les fréquences dites de résonance. Écouter de la musique dans une pičce revient donc ŕ écouter depuis l’intérieur d’un énorme instrument de musique qui émet ses propres notes lorsqu’il est acoustiquement excité (l’excitateur étant ici un haut-parleur au lieu d’un plectre, d’un archet ou d’une anche). Nulle surprise donc si les résultats musicaux ne sont pas toujours conformes aux attentes, particuličrement dans le grave oů se situent généralement ces résonances étant données les dimensions habituelles d’une pičce d’écoute.
Précisément, entre deux parois
parallčles distantes de L et réfléchissant les ondes acoustiques
peuvent se former des ondes stationnaires ŕ la fréquence v/2L,
oů v est la vitesses du son (environ 340m/s, variant avec la température),
plus ses harmoniques, c’est-ŕ-dire les multiples entiers de cette fréquence.
Voici en gros ce qui se passe :
- l’énergie rayonnée par un haut-parleur
part dans diverses directions, et donc forcément une partie se propage
selon un axe de la pičce ;
- sur la paroi, l’onde est réfléchie
et repart dans la direction d’oů elle vient ;
- au retour, elle croise les ondulations suivantes
qui sont elles en route vers la paroi et leurs énergies se combinent :
- elles s’annihilent lorsqu’elles sont exactement
opposées (la pression devient nulle et l’on parle d’un nœud de l’onde
stationnaire),
- elles s’additionnent lorsqu’elles sont exactement
superposées (on parle d’un ventre)
- le jeu se poursuit sur l’autre paroi, et ainsi
de suite.
Tout se passe évidemment trčs vite,
ŕ la vitesse du son, si vite que l’on n’entend pas la montée d’énergie
progressive de l’onde stationnaire mais son régime établi.
Résultats :
1. une augmentation considérable de l’énergie
de l’onde ŕ cette fréquence (comparativement aux fréquences
voisines qui ne sont de ce fait plus entendues) ;
2. mais une distribution trčs inégale
de cette énergie dans la pičce, avec des points (les nœuds) oů
l’on n’entend plus rien, d’autres (les ventres) oů l’on n’entend plus
que ça, et entre, toutes les situations intermédiaires.
L’expérience est facile ŕ faire de se
placer en différents points d’écoute, en s’intéressant
particuličrement aux parois et aux coins…
Conséquences pratiques :
1. Un égaliseur ne va évidemment
rien changer ŕ la résonance d’une salle, laquelle résulte
de sa géométrie. Tout ce qu’il peut faire, c’est filtrer les fréquences
qui excitent les modes propres de la salle. Ces résonances existent toujours,
mais n’étant plus excitées, les ondes stationnaires ne se forment
plus ou du moins ŕ un niveau suffisamment faible pour ne plus constituer
une gęne.
2. Les matériaux dont sont faites habituellement
les parois réfléchissent mieux les graves que les aigus, d’oů
une atténuation rapide des fréquences élevées et
des problčmes de résonance qui se manifestent surtout dans les
graves. Cela se traduit ŕ l’écoute par une amplification
considérable prenant la forme d’un gros ronflement (au point parfois
de faire vibrer portes et fenętres, et de voir le haut-parleur de grave
faire de telles excursions qu’on se demande s’il ne va pas ętre expulsé
du caisson !). Il arrive aussi qu’en certains points précis on n’entende
plus du tout ces fréquences.
3. Si le filtrage d’une résonance s’entendra
bien de partout (les fenętres ne vibreront plus !), en revanche une
correction précise, c’est-ŕ-dire une linéarisation de la
réponse sono-salle dans le grave, ne sera valable qu’au point d’écoute.
Avoir un bon réglage du grave est
important ŕ plusieurs titres :
1. C’est lŕ que se situe l’essentiel de
l’énergie de la musique. Exemples glanés sur le web : dans
american Life de Madonna, 24% de l’énergie acoustique totale est
en dessous de 50Hz, et dans le baiser d’Alain Souchon, c’est 15% de l'énergie
totale qui se trouve lŕ. Sachant que peu de systčmes de diffusion
passent grand chose en dessous de 50Hz, on imagine ce qu’on perd… Bien sűr,
d’aprčs le phénomčne de hauteur liée ŕ la
périodicité, le cerveau est capable de reconstituer des notes
graves en l’absence de la fondamentale grâce aux partiels. Mais d’une
part cela ne vaut que pour des notes, c’est-ŕ-dire des signaux acoustiques
caractérisés par une hauteur précise, d’autre part cela
reconstitue la sensation de hauteur mais pas l’énergie.
2. Les défauts dus aux résonances
s’entendent trčs bien dans le grave, souvent trop !
3. Il n’empęche que les corrections sont
difficiles ŕ faire ŕ l’oreille. En particulier lorsqu’il y a un
caisson de basses. En l’absence d’un égaliseur pour réduire drastiquement
le niveau des résonances, on a tendance ŕ placer trop haut la
fréquence de coupure et trop bas le volume du caisson. Cela ne sonne
pas trop bien. Tandis que lorsque le raccord est bien fait entre le caisson
et les enceintes principales, on constate que la fréquence de coupure
a été abaissée et le niveau sonore du caisson augmenté.
Si l’on arrive ŕ rendre parfaitement
plate la courbe de réponse sono-salle sur tout le spectre, eh bien l’on
n’est pas au bout de nos peines car le résultat sonne horriblement !
Je n’ai pas fait l’expérience mais tous ceux qui l’ont faite disent ŕ
peu prčs la męme chose : c’est agressif, dénué
de basses, pas naturel du tout. Je l’imagine bien. Oů est l’erreur ?
Lorsqu’un son voyage dans l’air les aigus s’atténuent
plus vite que les graves. Ce changement d’équilibre spectral est d’ailleurs
un moyen qu’utilise notre cerveau pour évaluer la distance d’une source
connue. Il est facile de vérifier l’existence du phénomčne
avec une chaîne hifi : écouter successivement la męme
séquence trčs prčs des enceintes puis le plus loin possible.
Nous sommes donc habitués ŕ percevoir
les différentes fréquences avec une courbe légčrement
descendante en allant vers les aigus. Voilŕ au moins un point sur lequel
tout le monde s’accorde. C’est quand on veut préciser de combien la courbe
doit descendre que les difficultés commencent. Car des courbes cibles
il en existe des tas. Par exemple :
1. Brüel et Kjaer n°1 : plate de 20Hz ŕ 400Hz puis descendant linéairement de 1dB par octave de 400Hz ŕ 20kHz
2. Brüel et Kjaer n°2 : plate de 20Hz ŕ 200Hz puis descendant linéairement de 0.5dB par octave de 200Hz ŕ 20kHz
3. Brüel et Kjaer n°3 : plate de 20Hz ŕ 100Hz puis descendant linéairement de 0.5dB par octave de 100Hz ŕ 20kHz
4. la norme ISO2969 pour auditoriums et salles de cinéma recommande une courbe plate de 20 ŕ 2000Hz puis descendant linéairement de 3dB/octave de 2000 ŕ 20.000Hz (soit une baisse de 10dB en tout)
5. la fonction AUTO-EQ du DEQ2496 dispose d’une option room correction qui modčle une courbe avec une pente de 1dB/oct
6. Tact de son côté propose sur ses ampli de nombreuses courbes, toutes descendantes, avec souvent un extręme grave proéminent…
La conclusion est claire : il n’y a pas de courbe cible idéale valable pour tous les goűts en tous lieux ! Ceci dit, comment faire en pratique pour choisir sans avoir ŕ passer des heures et des heures en tests ? Voici quelques lignes directrices :
- plus la pičce est petite, plus la décroissance doit ętre forte du grave ŕ l’aigu ;
- plus on écoute prčs des enceintes, plus la décroissance doit ętre forte du grave ŕ l’aigu ;
- au-dessus de 1 ou 2kHz, essayer d’aller dans le sens de la réponse de la pičce et éviter les corrections démentielles pour obtenir ŕ n’importe quel prix tel ou tel résultat.
Dans un second temps, on peut peaufiner,
par exemple :
Rehausser un peu la courbe dans les aigus pour une
sonorité plus brillante. Toutefois ce n’est pas la peine de relever exagérément
l’aigu trčs extręme. D’abord il convient de vérifier qu’il
est bien entendu (c’est facile avec des séquences de balayage de 20Hz
ŕ 20kHz) : personnellement je n’entends plus grand chose au-delŕ
de 16kHz. Ensuite il faut vérifier la qualité de cet aigu, certains
convertisseurs DA produisant des effets de moirage. Sans compter que cet aigu
extręme ne vaut de toute maničre pas grand chose en qualité
CD 16bits-44.1kHz.
Si on les apprécie et qu’on a bien
corrigé les résonances boum-boum, on peut rehausser un peu les
graves. Mais attention :
- inutile de prolonger une courbe en dessous
de la fréquence la plus basse que le systčme est capable de reproduire ;
- ne pas augmenter exagérément
les graves si l’ampli et les enceintes ne sont pas capables d’encaisser :
risque de casse !
On peut choisir aussi de creuser un peu le médium ou, ce qui revient au męme, mettre en avant le grave et l’aigu. C’est intéressant avec des enceintes bas rendement qui passent mal la puissance, ou si l’on a l’habitude d’écouter ŕ niveau peu élevé. Cela revient en fait ŕ intégrer une correction loudness. Voilŕ qui fait le lien avec la psychoacoustique.
non-linéarité des courbes de sensibilité de l’oreille
L’expérience est trčs facile
ŕ faire avec les séquences de balayage de fréquences :
1. lancer la séquence 2800-3050-3300-3550
(ceci fait référence au cd test que j’ai réalisé ;
il est décrit dans appareils_musiques-ea.pdf)
et régler le volume de façon qu’elle soit tout juste audible ;
2. sans toucher au volume, écouter les
autres séquences et constater lesquelles sont audibles et lesquelles
ne le sont pas ;
3. augmenter trčs légčrement
le volume et recommencer l’écoute de toutes les séquences…
Sachant que toutes les séquences ont été
réalisées au męme niveau d’intensité, ceci permet
de constater que la sensibilité de l’oreille varie trčs fortement
avec la fréquence et avec le volume : une fréquence d’une
certaine intensité va ętre entendue tandis qu’une autre de męme
intensité ne le sera pas ; et quand on change le volume d’écoute,
le tableau des fréquences entendues et pas entendues change aussi. Les
courbes d’isosonie qui relient sensation d’intensité sonore, fréquence,
et intensité de l’onde acoustique, récapitulent cela de maničre
plus précise. Les voici dans leur derničre version ISO226 de 2003 :
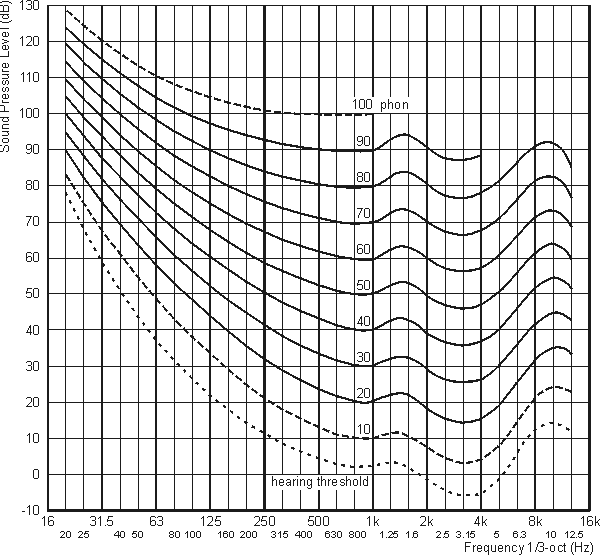
Conséquences :
1. Les fréquences extręmes ne sont
pas entendues du tout tant que le volume n’atteint pas un certain seuil.
2. Changer le volume d’écoute d’un signal
acoustique complexe (c’est-ŕ-dire constitué de nombreuses fréquences)
revient ŕ changer son équilibre spectral (c’est-ŕ-dire
la maničre dont sont entendues les différentes fréquences
qui le constituent). Certaines fréquences peuvent męme sembler
apparaître soudain ou disparaître complčtement. Du coup on
en arrive ŕ interpréter comme changement de volume de simples
modifications de l’équilibre spectral du son.
3. Quand le son est bien équilibré
pour un certain niveau d’écoute, diminuer le volume de 3 voire 6dB n’est
pas gęnant. L’inverse n’est pas vrai car en augmentant le volume certaines
fréquences élevées peuvent surgir au premier plan et perturber
notablement l’écoute.
4. Lorsqu’on pense : " c’est trop
fort ", il faut souvent interpréter : l’augmentation de
volume a déséquilibré le spectre, faisant ressortir exagérément
certaines fréquences qui elles, et elles seules, sont irritantes par
leur intensité et font percevoir l’ensemble comme désagréablement
trop fort. Notre perception des changements de volume et l’irritation qui peut
en résulter est la plus forte dans la zone de sensibilité maximale
2000-5000Hz, d’oů il s’ensuit que diminuer un peu l’intensité
dans cette zone permet d’augmenter le volume global sans plus provoquer de gęne.
5. Notre systčme auditif pardonne plus
facilement les défauts d’équilibre ŕ bas qu’ŕ haut
volume (peut-ętre parce qu’il est capable de reconstituer jusqu’ŕ
un certain point des fréquences manquantes : cf. le phénomčne
de hauteur liée ŕ la périodicité). Mais męme
si le message sonore reste ‘lisible’ (cf. la qualité ‘téléphone’
avec des voix et des intonations reconnaissables malgré une bande passante
réduite), il est considérablement dénaturé, surtout
pour la musique. C’est dans le grave jusqu’aux environs de 200Hz que se situe
la majorité des fondamentales des instruments qui donnent ŕ la
musique son assise rythmique et son énergie. Couper cela, et la musique
y perd considérablement.
correction selon le niveau d’écoute
La disparition des graves et des aigus ŕ
faible niveau d’écoute est connue depuis longtemps. Et exploitée
depuis presque aussi longtemps : c’est la fonction loudness présente
sur de nombreux amplis. Les résultats étant jugés pas toujours
du meilleur goűt par les audiophiles, elle est rarement mise en œuvre
sur les amplis hi-fi moyen et haut de gamme, ce qui interdit pratiquement toute
écoute ŕ faible volume sur des enceintes ŕ haut rendement
(les enceintes bas rendement qui ne tolčrent pas en général
les fortes puissances intčgrent souvent dčs leur conception un
léger retrait du médium par rapport au grave et ŕ l’aigu).
Elle reparaît aujourd’hui sur quelques appareils haut de gamme, avancées
en psychoacoustique et en traitement du signal aidant.
Pourquoi des résultats pas toujours satisfaisants
alors que les courbes de réponse de l’oreille sont bien établies ?
En fait pas si bien établies : les courbes actuelles ISO226-2003
présentent des écarts importants avec les plus anciennes, beaucoup
moins précises, mais qui ont tout de męme, faute de mieux, longtemps
servi de référence pour concevoir des correcteurs loudness
(courbes de Fletcher-Munson de 1933 et de Robinson-Dadson de 1956 ŕ la
base de la norme ISO226-1961).
D’autre part, pour ętre en mesure d’appliquer
une correction, il faut savoir au moins d’oů l’on part, c’est-ŕ-dire
connaître le niveau de référence auquel a été
réalisé le master de l’enregistrement, ce qui est loin d’ętre
toujours le cas. La courbe d’isosonie la plus plate est ŕ 85dB SPL référence
ŕ 1kHz, soit par définition 85 phones. Cela devrait ętre
théoriquement le niveau sonore normalisé. C’est le cas pour les
films, pas tout ŕ fait pour la musique. En fait, beaucoup d’enregistrements
se situent nul ne sait oů : cf. tous les vieux enregistrements,
cf. les concerts sonorisés ŕ crever les tympans transformés
en CD voire en mp3, cf. des instruments descendant trčs bas dans le grave,
lŕ oů la plupart des enceintes ne vont pas sans l’appoint d’un
caisson de basses…
Et ce n’est pas le seul problčme ! Il
est difficile en pratique d’égaliser chaque programme musical pour tenir
compte ŕ la fois : du niveau d’écoute (lequel est d’ailleurs
difficile ŕ évaluer sans expérience ou sans un appareil
de mesure), comparativement au niveau pour lequel a été réalisé
le master de l’enregistrement (lequel est souvent incertain on l’a dit), sans
parler des limites de la sono, de la sensibilité particuličre
de l’oreille de l’auditeur (les courbes d’isosonie sont des moyennes statistiques),
sans parler non plus des écarts importants de dynamiques ŕ l’intérieur
d’un męme morceau entre passages ppp et tutti fff (c’est
pourquoi les appareils les plus récents incluent la dénomination
dynamique pour signifier qu’ils adaptent dynamiquement les filtres qu’ils
appliquent au contenu instantané du programme).
Malgré tout, il est possible d’obtenir des corrections satisfaisantes avec un égaliseur graphique. Il n’est pas trčs difficile de programmer quelques courbes correctives ŕ appliquer en cas d’écoute ŕ faible volume sur une chaîne hi-fi telle que la mienne qui n’est pas vraiment conçue pour ça (haut rendement, 92 dB pour 1W ŕ 1m, et courbe de réponse en chambre sourde parfaitement plate). Le but est qu’au moins, dans ces conditions de jeu, elle donne autant ŕ entendre qu’un minuscule baladeur ŕ 30 euros pourvu d’un bass boost ! Considérant que les concepteurs de ces nouveaux appareils ont dű bien étudier la question, autant s’en inspirer. Voici les courbes du Tact qui peuvent servir de point de départ :
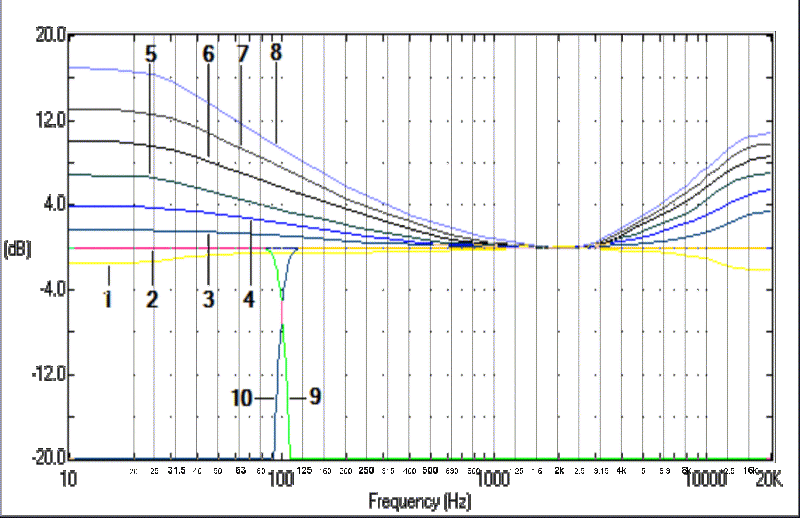
1. écoute ŕ +6dB
2. courbe plate, niveau d’écoute de référence
3. écoute ŕ -6dB
4. -12dB
5. -18dB
6. -24dB
7. -30dB
8. -36dB
Les tableaux suivants sont une adaptation des courbes 3 ŕ 7 pour un égaliseur 31 bandes (le signe ~ signifiant une interpolation entre la valeur précédente et la suivante)
|
20 |
25 |
31.5 |
40 |
50 |
63 |
80 |
100 |
125 |
160 |
200 |
250 |
315 |
400 |
500 |
|
|
3 |
+2 |
+2 |
~ |
~ |
~ |
~ |
~ |
~ |
+1 |
~ |
~ |
~ |
~ |
0 |
0 |
|
4 |
+4 |
~ |
+3.5 |
~ |
+3 |
~ |
+2.5 |
~ |
+2 |
~ |
+1.5 |
~ |
+1 |
+0.5 |
0 |
|
5 |
+7 |
+6.5 |
+6 |
+5.5 |
+5 |
+4.5 |
+4 |
+3.5 |
+3 |
+2.5 |
+2 |
~ |
~ |
+1 |
+0.5 |
|
6 |
+10 |
+9.5 |
+9 |
+8.5 |
+8 |
+7.5 |
+7 |
+6 |
+5 |
+4 |
+3.5 |
+3 |
+2.5 |
+2 |
+1.5 |
|
7 |
+13 |
12.5 |
+12 |
11.5 |
+11 |
+10 |
+9 |
+8 |
+7 |
+6 |
+5 |
+4 |
+3 |
+2.5 |
+2 |
|
630 |
800 |
1k |
1.25 |
1.6 |
2 |
2.5 |
3.15 |
4 |
5 |
6.3 |
8 |
10 |
12.5 |
16 |
20 |
|
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
+0.5 |
~ |
+1 |
+1.5 |
+2 |
+3 |
+3.5 |
|
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
+0.5 |
+1 |
+1.5 |
+2 |
+3 |
+4 |
+4.5 |
+5 |
|
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
+0.5 |
+1.5 |
+2 |
+3 |
+4.5 |
+6 |
+6.5 |
+7 |
|
+1 |
+0.5 |
0 |
0 |
0 |
0 |
0 |
+0.5 |
+1 |
+2 |
+3 |
+4.5 |
+6 |
+7 |
+8 |
+9 |
|
+1.5 |
+1 |
+0.5 |
0 |
0 |
0 |
0 |
+0.5 |
+1.5 |
+2.5 |
+4 |
+6 |
+7 |
+8 |
+9.5 |
+10 |
fatigue auditive
J’ai souvent remarqué une certaine fatigue auditive aprčs avoir écouté de la musique sur ma chaîne hifi comparativement ŕ une écoute non sonorisée (je n’éprouve jamais cela non plus lorsque je joue du saxophone, instrument pas vraiment réputé pour ses pianissimos). Cela apparaît sans avoir ŕ pousser exagérément le volume. Parfois cela prend la forme d’une tension physique qui peut ętre en contradiction avec le genre de musique écoutée. Sans que ce soit éprouvant (ce n’est quand męme pas comme passer une heure devant un mur d’enceintes ŕ un concert rock), c’est gęnant pour moi dans la mesure oů cela fait perdre la sensation d’immersion dans le son que j’apprécie tant, un peu comme lorsqu’on réalise que l’eau du bain a refroidi et que ce n’est plus si agréable d’y rester. J’ai fini par identifier plusieurs causes ŕ cette fatigue : l’une concerne une mise en avant du médium et sera traitée dans un prochain paragraphe, l’autre se situe dans les aigus et fait l’objet de celui-ci. Ce problčme des aigus se scinde lui-męme en deux: problčme ŕ la prise de son et problčme ŕ la reproduction.
prise de son
Le problčme des aigus commence dčs
la prise de son. J'ai fait cette découverte lors de mes recherches d'un
micro pour enregistrer mon saxophone: les courbes de réponses de la
plupart des micros sont loin d'ętre linéaires, avec une tendance
générale ŕ une remontée dans les aigus. Deux exemples:
- le SM58 de Shure, micro de scčne quasi universel pour la voix (mais
parfois aussi utilisé sur des instruments comme le saxophone):
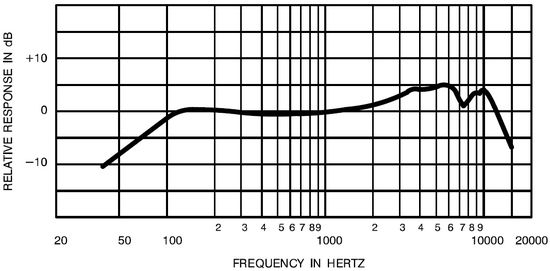
- le Neumann U87 (ici dans la
version Ai la plus récente), micro de studio de référence pour la voix.
Courbe de réponse présentée ici pour la position ominidirectionnelle:
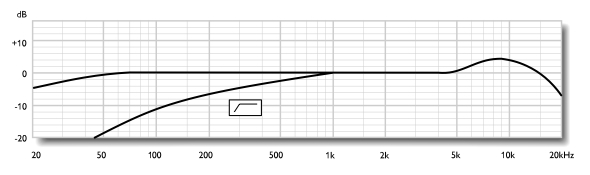
On note dans les deux cas une
remontée trčs nette jusqu'ŕ 5dB dans les aigus, commençant vers 5kHz
avec un pic vers 8kHz pour le U87, et commençant vers 2k avec un
maximum entre 3.5 et 6k pour le Shure. Notons que ce ne sont pas les
pires, certains micros présentant des pics ŕ prčs de 10dB. Et si des
micros comme le U87 ci-dessus ont leur pic ŕ une fréquence relativement
élevée, un trčs grand nombre remontent dčs 2kHz, parfois avant, avec un
maximum en plein dans la zone de sensibilité maximale de l'oreille.
C'est intentionnel évidemment, le but étant de faire ressortir
davantage telle voix (ou tel instrument) dans le mix. Et comme tout le
monde veux ętre entendu, comme le moindre enregistrement requiert
aujourd'hui un grand nombre de micros, on assiste ŕ une compétition qui
aboutit ŕ déséquilibrer l'enregistrement.
reproduction: distorsion harmonique
Le problčme des aigus est amplifié lors de la reproduction ŕ cause de la distorsion harmonique.
La plupart des instruments de l’orchestre ont une
étendue qui rentre dans l’intervalle 50Hz-1500Hz (c'est-ŕ-dire la fondamentale des notes) avec des incursions
en deçŕ et au-delŕ pour quelques uns d’entre eux. Quant
aux voix, de la basse ŕ la soprano, elles s’étendent de 70 ŕ
1000Hz environ. Dans la zone de sensibilité maximale de l’oreille qui
s’étend elle de 2000 ŕ 5000Hz, se situent ŕ la fois les
premiers harmoniques des notes aiguës et les harmoniques de rangs élevés
des notes graves. Lors d’une écoute naturelle c’est-ŕ-dire sans
le biais d’une sono, l’oreille perçoit fort bien tous ces harmoniques.
Loin d’en ętre gęnée, ils contribuent ŕ l’intelligibilité
du message sonore, qu’il s’agisse de paroles ou de musiques.
Les choses se passent différemment lors d’une
écoute ŕ travers un systčme de sonorisation (que ce soit
en direct ou en reproduction). La distorsion harmonique (DH) vient semer
la zizanie. Cela peut sembler surprenant puisqu’on sait faire aujourd’hui des
enceintes qui exhibent des taux de DH inférieurs ŕ 1%, et des
amplis ŕ transistors des valeurs encore moindres (et męme carrément
nulles pour les amplis dits numériques). Un exemple va rendre cela compréhensible :
accumulation d’harmoniques dans la zone
de sensibilité maximale
Pour rendre les choses plus explicites, partons d’une
note assez basse, disons le la2 ŕ 103.8Hz, que je m’empresse d’arrondir
ŕ 100 pour faciliter les calculs en rentrant dans le découpage
ISO du spectre en tiers d’octaves. 100Hz, cela sonne grave, mais : beaucoup
d’instruments et quelques voix descendent encore plus bas (on est encore ŕ
2 octaves du bout d’un piano), et quasiment tous les systčmes de diffusion
reproduisent sans problčme cette fréquence.
Considérant la fondamentale comme une fréquence
isolée, attribuons-lui une sensation de volume sonore de 65dB/40 phones
ou 72dB/50 phones.
Que le systčme de diffusion produise de la
DH signifie qu’en plus de cette fréquence de 100Hz il va fabriquer des
fréquences harmoniques, jusqu’ŕ, pourquoi pas, 3200Hz qui est
situé dans la zone de sensibilité maximale.
Le processus est cumulatif et męme doublement
cumulatif : chaque harmonique produit par l’instrument est vu par l’ampli
comme une fondamentale qui va ŕ son tour générer des harmoniques ;
et chacune de ces fréquences sortant de l’ampli est ŕ son tour
une fondamentale pour les hauts parleurs qui engendrent aussi leurs harmoniques.
C’est ainsi qu’on retrouve étalées sur une bonne partie du spectre
tout un tas de fréquences harmoniques qui ne sont pas présentes
dans le signal sonore initial ou ŕ des intensité bien moindres.
La plupart ne perturbent pas l’écoute parce que, les taux de distorsion
des appareils étant faibles, elles ne ressortent pas. Sauf celles qui
tombent dans la zone de sensibilité maximale de l’oreille.
Si l’on se réfčre aux courbes d’isosonie :
ŕ 40 phones, l’oreille est plus sensible d’environ 27dB ŕ 3200Hz
qu’ŕ 100Hz. 27dB, cela représente un rapport de puissance de 502
(1.25927). Cela signifie qu’avec une intensité 500 fois plus
faible (0.2%) que la fondamentale, l’harmonique ŕ 3200Hz est perçue
exactement au męme niveau sonore. Et ŕ 50 phones, l’écart
est encore de 25dB, soit un rapport de puissance de 316, de sorte qu’un harmonique
ŕ 3200Hz dont l’intensité vaut seulement 0.3% celle de la fondamentale
est perçue au męme niveau.
Ce fait combiné avec le phénomčne
d’accumulation des harmoniques suggčre qu’il suffit vraiment de peu de
choses pour perturber l’audition. C’est ainsi qu’on peut se retrouver avec un
aigu qui ressort exagérément dans la zone de sensibilité
maximale au point de rendre l’écoute fatigante, et ce malgré des
appareils de diffusion de qualité.
complément sur la zone de sensibilité
maximale
On peut se demander pourquoi il est plus gęnant
que la bande 2000-5000Hz ressorte davantage qu’une autre, autrement dit pourquoi
c’est irritant et pas seulement plus fort. La sensibilité est maximale
dans cette zone ŕ cause de résonances dans le conduit auditif.
Voici une autre expérience facile ŕ faire qui le confirme :
sélectionner un morceau de musique assez riche sur l’ensemble du spectre,
par exemple le chœur introductif de la messe en si de Bach qui comprend l’orchestre
au complet, des voix de femmes et des voix d’hommes ; commencer avec l’égaliseur
graphique complčtement ŕ plat, puis sélectionner une bande
large d’une octave, trois tirettes donc, qui sont remontées ŕ
fond ; écouter, remettre les tirettes ŕ zéro et passer
ŕ l’octave d’ŕ côté… On remarque lorsqu’on arrive
ŕ la bande 2500-3150-4000Hz que l’effet est plus gęnant qu’ailleurs,
comme si effectivement il se passe quelque chose dans le conduit auditif, que
le son en quelque sorte s’amplifie.
corrections
Il existe des systčmes de diffusion qui engendrent
moins ces tensions que d’autres, et ce sans afficher des taux de distorsion
plus faibles. Je soupçonne qu’un certain degré d’égalisation
est introduit subrepticement, par exemple par un petit creux dans la courbe
de réponse des enceintes, voire par les câbles.
Sinon il faut recourir ŕ l’égaliseur.
Le hic est qu’il intervient toujours avant le systčme de diffusion qui
génčre la DH (tous les égaliseurs ŕ ma connaissance
fonctionnent au niveau ligne et ne sont pas conçus pour encaisser les
courants forts qui sortent des amplis). On est donc en droit de se demander
s’il est d’une réelle utilité : étant donné
cet ordre imposé, l’égaliseur ne peut agir que sur l’équilibre
spectral du signal source encore dépourvu de DH, pas sur ce qui sort
de l’ampli, et encore moins sur les vibrations des membranes des haut-parleurs.
Tout ce qu’il possible de faire, c’est diminuer l’intensité des harmoniques
naturels dans la zone critique de sensibilité maximale. Cela revient
en quelque sorte ŕ leur substituer des harmoniques artificiels générés
par DH. Cela peut sembler radical, surtout pour un audiophile. Mais ce n’est
finalement pas plus artificiel que les distorsions en tous genres que produisent
les amplis ŕ tubes (ce dont attestent incontestablement des mesures peu
flatteuses en regard de leurs homologues ŕ transistors) mais qui sont
pourtant fort prisés desdits audiophiles pour leur musicalité.
Sans compter les distorsions encore plus importantes générées
par le simple fait d’écouter un morceau ŕ un niveau différent
de celui du mixage parce que les variations de sensibilité de l’oreille
ne sont pas prises en compte. Tout dépend finalement de ce que l’on souhaite
reproduire : des bits ou bien de la musique ? Corriger ŕ l’égaliseur
la zone 2-5kHz pour retrouver un niveau sonore plus ‘naturel’ dans cette zone
ne me semble pas plus antimusical que tout ce qui vient d’ętre évoqué.
D’oů il s’ensuit qu’un égaliseur devrait faire partie de l’équipement
de base de tout bon audiophile. Mais c’est une autre histoire… Quoiqu’il en
soit il fait désormais partie de mon équipement.
Pour terminer, voici quelques courbes de correction pour commencer ŕ jouer :
|
2k |
2.5 |
3.15 |
4 |
5 |
|
0 |
-1.5 |
-2 |
-1.5 |
0 |
|
0 |
-2 |
-3 |
-2 |
0 |
Il y en a d’autres, par exemple les programmes music1 et music2 du correcteur acoustique Lyngdorf RP-1, destinées ŕ l’écoute de la musique comme leur nom l’indique :
|
630 |
800 |
1k |
1.25 |
1.6 |
2 |
2.5 |
3.15 |
4 |
5 |
6.3 |
8 |
10 |
12.5 |
|
0 |
~ |
-0.5 |
-1 |
-2 |
-2.5 |
-2 |
-1 |
-0.5 |
~ |
0 |
|||
|
0 |
~ |
-0.5 |
~ |
-1 |
-2 |
-3 |
-2.5 |
-2 |
-1 |
~ |
-0.5 |
~ |
0 |
La comparaison avec les précédentes révčle de curieuses différences. Ces courbes ressemblent bien ŕ des courbes de réduction des harmoniques dans la zone de sensibilité maximale de l’oreille. Mais on note qu’en dessous de 2000Hz elles ne s’accordent pas avec les actuelles courbes d’isosonie, lesquelles montrent une nette perte de sensibilité entre 1000 et 2000Hz. Une explication possible est qu’elles ne sont pas basées sur les derničres courbes ISO226-2003 compilées ŕ partir des expériences les plus récentes, mais sur des anciennes beaucoup moins précises. Il est un fait que les classiques courbes de Fletcher-Munson de 1933, qui ont longtemps servi de référence (entre autres aussi pour des correcteurs loudness), n’exhibent pas ce sursaut entre 1000 et 2000Hz. Une petite remontée des courbes dans cette zone signifiant une légčre baisse de sensibilité commence ŕ apparaître sur celles de Robinson et Dadson de 1956 sur quoi repose la norme ISO226-1961. Quoiqu’il en soit, cela ne veut pas dire que ces deux programmes music1 et music2 ne sont pas intéressants. Je ne saurais en dire plus, je ne les ai pas testées. En tout cas leur présence sur un tel appareil me conforte quant ŕ l’intéręt pour l’écoute de la musique d’une correction dans la zone de sensibilité maximale.
conclusions
Les corrections tenant compte de la sensibilité
de l’oreille permettent :
- dans le grave et l’aigu de garder un contenu
musical riche ŕ faible volume,
- de corriger la zone 2000-5000Hz pour pouvoir
écouter sans fatigue ni tension ni autres désagréments
parfois subliminaux,
- de pouvoir écouter plus fort plus longtemps
sans ressentir de gęne ni que le systčme auditif soit affecté.
Le but pour moi au final est de faciliter l’immersion
dans le son, trčs importante dans les musiques de sons. Ŕ condition
de résoudre un dernier problčme, la fatigue auditive causée
par le registre médium.
fatigue auditive, suite
Un petit tour sur les forums audiophiles
révčle que la fatigue auditive n’est pas chose rare, y compris
avec des matériels haut de gamme et sans qu’il soit besoin d’écouter
trčs fort ni trčs longtemps (je ne parle pas bien sűr d’acouphčnes
et autres bourdonnements dus ŕ une exposition prolongée ŕ
des trčs forts niveaux sonores). Outre l’accumulation des harmoniques
dans la zone de sensibilité maximale que l’on vient d’étudier,
il y a de nombreuses autres causes :
- des enregistrements abusant de la compression
pour produire un son le plus fort possible (ce qui se neutralise facilement
en baissant le volume mais doit ętre compensé par une correction
loudness pour retrouver tout le contenu) mais surtout avec trčs peu de
dynamique (écart de quelques dB seulement entre les sons les plus forts
et les sons les plus faibles) ; résultat : l’oreille n’a jamais
le temps de se reposer et elle finit par saturer ;
- la présence de bruits et autres parasites
qui obligent ŕ un effort de concentration pour extraire le message sonore
(mais tous les bruits ne sont pas forcément gęnants : les
bruits de fond ŕ spectre large des vinyles et des cassettes ne perturbent
gučre l’écoute, ils passent męme inaperçus aprčs
quelques secondes) ;
- des distorsions provenant de non-linéarités
prononcées du systčme lorsque les différents éléments
ne s’accordent pas bien entre eux ou que l’un est de qualité médiocre ;
cela se traduit par des creux et des pics dans la courbe de réponse qui
rendent certaines fréquences plus audibles et d’autres moins, et font
qu’on n’arrive jamais ŕ trouver un réglage de volume correct ;
- de légčres colorations de la
source, de l’ampli, des enceintes, de la salle, qui, en s’additionnant, font
que certains registres ressortent systématiquement, ce qui peut ętre
flatteur dans un premier temps mais qui ŕ la longue provoque de la fatigue
auditive.
Ce dernier cas me concerne, avec, il me semble, une
mise en avant du médium. Cela produit effectivement un trčs beau
son, notamment sur les voix. Ce n’est pas une surprise sachant que les enceintes
Araxe premičre génération ont été
particuličrement travaillées pour le rendu des voix (dixit l’un
des concepteurs, Christian Avedissian lors d’une communication personnelle),
sachant qu’en outre l’ampli John Shearne phase2 favorise lui aussi le
médium. Certes le grave est profond et dynamique, l’aigu bien filé,
mais reste que dans l’ensemble le médium est privilégié.
Cette mesure (avant toute correction évidemment) de la réponse de mon systčme ŕ un bruit blanc le confirme :
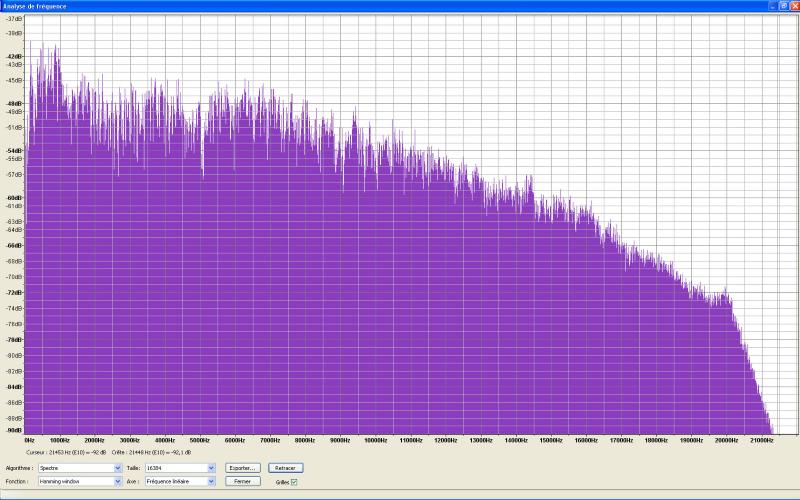
Un pic prononcé entre 400 et 1200Hz
est trčs nettement visible (tout en haut ŕ gauche). Notons aussi
la remontée autour de 3700Hz, certes moins proéminente mais gęnante
parce que située en plein dans la zone de sensibilité maximale,
et une autre encore autour de 6500Hz mais qui n’est pas gęnante parce
qu’il y a également remontée des courbes de sensibilité
de l’oreille ŕ partir de 5000Hz.
Cette mise en avant du médium peut aussi ętre
interprétée comme un léger retrait des autres registres.
D’oů l’envie d’un peu plus de graves pour se sentir davantage immergé
dans le son, et pour ce faire le réflexe d’augmenter le volume. Certes
les basses s’en trouvent augmentées, mais le problčme n’est pas
résolu puisque le médium augmente dans les męmes proportions.
Et comme, ŕ quelque niveau d’écoute que ce soit, l’oreille est
plus sensible dans le médium que dans le grave, il reste toujours en
avant. D’oů finalement cette fatigue auditive qui s’installe.
Le problčme n’est soluble qu’avec un égaliseur
qui va permettre de rétablir l’équilibre sur l’ensemble du spectre.
méthode de correction
AUTO-EQ ou analyse séparée ?
Le DEQ2496 possčde une fonction AUTO-EQ qui permet, en branchant dessus un micro de mesures et en se donnant une courbe de réponse cible, d’effectuer automatiquement ŕ l’égaliseur graphique les corrections requises pour l’atteindre. Quoi de plus simple ? Eh bien, je préfčre quand męme ne pas l’utiliser pour un certain nombre de raisons :
1. La plus importante est que cette fonction agit sur l’égaliseur graphique, avec donc certains des défauts inhérents ŕ ce genre d’appareil déjŕ évoqués : manque de précision dans le réglage des fréquences ŕ corriger et manque de précision de la largeur de la bande corrigée autour de cette fréquence. Seul un égaliseur paramétrique est suffisamment précis pour corriger correctement des courbes de réponse tourmentées. Et avec le DEQ2496 il y a de quoi faire : 10 filtres (en mode stereo link ou 2x10 en mode dual mono) réglables chacun en fréquence au 1/60 d’octave, en largeur de 1/10 ŕ 10 octaves, et en gain de -15 ŕ +15 dB.
2. Si l’AUTO-EQ n’est pas utilisé, force est de séparer la chaîne de production de sons tests (source + égaliseur + ampli + enceintes + salle) de la chaîne d’analyse (micro + enregistreur + analyseur de spectre). C’est évidemment un peu plus compliqué. Mais cela présente aussi un avantage, celui de pouvoir opérer des corrections sur le DEQ et d’en observer immédiatement les effets.
3. De toute maničre, le manuel du DEQ2496 recommande de ne pas employer l’AUTO-EQ en dessous de 100Hz ŕ cause de possibles erreurs de calculs dans ce registre. Or c’est souvent lŕ que se situent les principaux problčmes acoustiques : résonances de salle, et jonction entre les enceintes principales et le caisson de basses (lequel, pour compliquer les choses, possčde en général ses propres réglages de volume et de fréquence de coupure). Donc, męme si l’on se sert de l’AUTO-EQ pour corriger le médium et l’aigu, il faut une autre procédure pour corriger le grave (sauf bien sűr ŕ avoir des enceintes qui ne descendent pas trčs bas et pas de caisson). Autant se simplifier et n’en avoir qu’une !
4. Enfin, je préfčre travailler les corrections par couches successives :
1. corrections dans le grave (essentiellement
au paramétrique),
2. corrections dans le médium et l’aigu
avec application d’une courbe-cible (essentiellement au graphique, AUTO-EQ
possible donc mais autant employer de bout en bout la męme procédure),
3. corrections psychoacoustiques.
Tout ceci est possible en constituant deux
circuits indépendants :
1. production du son : CD ŕ
DEQ ŕ ampli ŕ
enceintes+caisson
2. captation et analyse : micro de mesures
ŕ interface audio ŕ
ordinateur + logiciel de traitement audio
Dans mon cas, l’interface audio comprend :
1. la loop-station Boss RC50, qui ne me sert
en fait que pour son alimentation fantôme nécessaire pour faire
fonctionner le micro de mesures,
2. l’égaliseur DEQ1024, qui me sert ŕ
corriger les petites irrégularités dans la courbe de réponse
du micro,
3. un Phonic Digitrack, qui permet de prendre
la sortie numérique du DEQ1024 pour l’envoyer dans l’ordinateur sur lequel
tourne le logiciel d’édition audio Audacity (http://audacity.sourceforge.net).
On peut faire plus simple, j’en conviens. Disons que je fais avec le matériel dont je dispose. Mais la méthode exposée ici reste valable sans tout ça. Il faut juste une interface audio disposant d’une alimentation fantôme pour envoyer le signal capté par un micro de mesures dans un ordinateur. La correction de la courbe de réponse du micro peut alors se faire avec l’égaliseur graphique intégré ŕ Audacity.
bruits tests
Qu’est-ce qu’on analyse ? Il existe
en gros deux méthodes :
1. réponse ŕ des signaux impulsionnels,
2. réponse ŕ des bruits blanc et
rose.
Dans les deux cas la chaîne hifi émet un signal acoustique, lequel est capté par un micro de mesures (micro spécial ayant une courbe de réponse la plus plate possible sur tout le spectre audible 20Hz-20kHz) et analysé avec un logiciel ad hoc. La premičre méthode est censée ętre beaucoup plus précise car, outre la réponse en fréquence, elle permet aussi la mesure de décalages temporels. On trouve aujourd’hui sur le web tout ce qu’il faut pour généré de tels signaux impulsionnels et analyser les réponses. C’est certes trčs précis mais pas facile ŕ comprendre et ŕ mettre en œuvre. Me sentant davantage musicien qu’audiophile, je ne tiens pas ŕ passer un temps infini ŕ régler d’infimes détails, pas toujours décelables ŕ l’écoute d’ailleurs. Je préfčre donc recourir ŕ la méthode plus simple et éprouvé d’analyse de bruit, męme si c’est plus grossier.
Un bruit est par définition un signal
constitué d’un mélange de toutes les fréquences audibles.
De lŕ son intéręt en acoustique : pouvoir tester la
réponse d’un systčme sur tout le spectre avec une seule séquence
sonore. Le DEQ2496 dispose de son propre générateur de bruit rose.
Mais il n’est pas utilisable dans ma configuration puisque je veux que les signaux
qui passe ŕ travers lui soient traités par les modules GEQ et
PEQ. En outre je ne suis pas sűr de sa qualité : j’ai analysé
un échantillon de bruit rose généré par son petit
frčre le DEQ1024 et il se révčle pas du tout conforme ŕ
un vrai bruit rose descendant réguličrement de 3dB/octave de 20Hz
ŕ 20kHz. Etant donné ce que je veux faire, le mieux est d’enregistrer
des échantillons de bruits sur un CD. Ça permet :
- d’avoir des bruits rose et blanc parfaitement conformes,
ce qui facilite l’analyse : j’y reviens dans un instant ;
- de pouvoir procéder ŕ des corrections
ŕ la volée puisque le signal passe ŕ travers le DEQ ;
- de tester toute la chaîne, du lecteur
CD au local d’écoute ;
- de créer des échantillons séparant
les canaux gauche et droit afin de mettre en évidence d’éventuelles
asymétries (mon ampli ‘minimaliste’ ne dispose évidemment pas
d’un bouton de balance !).
bruit blanc
Dans un bruit blanc, l’énergie est également
répartie sur tout le spectre. Autrement dit, il y a autant d’énergie
entre 0 et 10.000Hz qu’entre 10.000 et 20.000. Cela rend un tel signal approprié
pour l’analyse de l’aigu. Affiché en mode linéaire, le spectre
d’un bruit blanc donne ceci : une courbe plate.
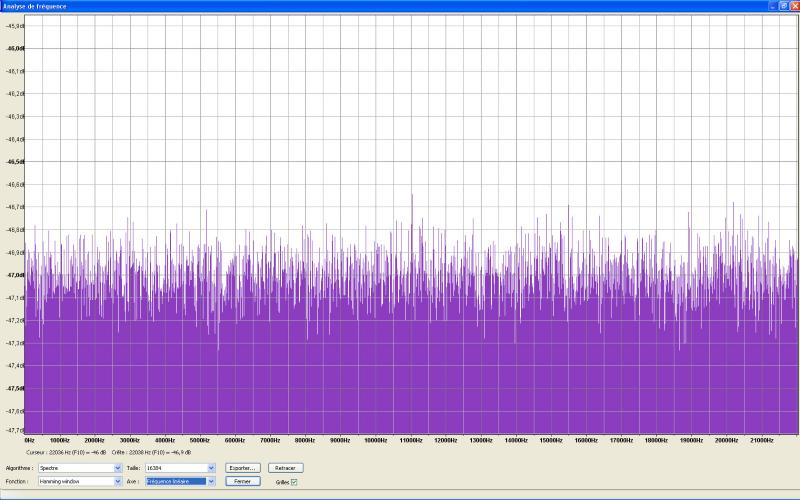
Remarques :
- tous les échantillons de bruits utilisés
ici ont été générés avec Audacity,
- et analysés avec l’analyseur de spectre
de Audacity configuré sur la taille maximale de 16324 (employer la version
1.3.8 ou supérieure, l’analyseur de spectre est moins performant sur
les versions antérieures) ;
- si ça semble un peu brouillon par rapport
ŕ des courbes de réponses présentées dans les manuels
des constructeurs, c’est qu’elles ne sont pas lissées.
bruit rose
En comparaison, un bruit rose a une énergie
également répartie par octaves. Il y a donc autant d’énergie
entre 20 et 40Hz qu’entre 10.000 et 20.000Hz. Cela rend un tel bruit particuličrement
approprié ŕ l’analyse du grave et du médium. En affichage
logarithmique, son spectre montre une descente parfaitement linéaire
de 3dB/octave :
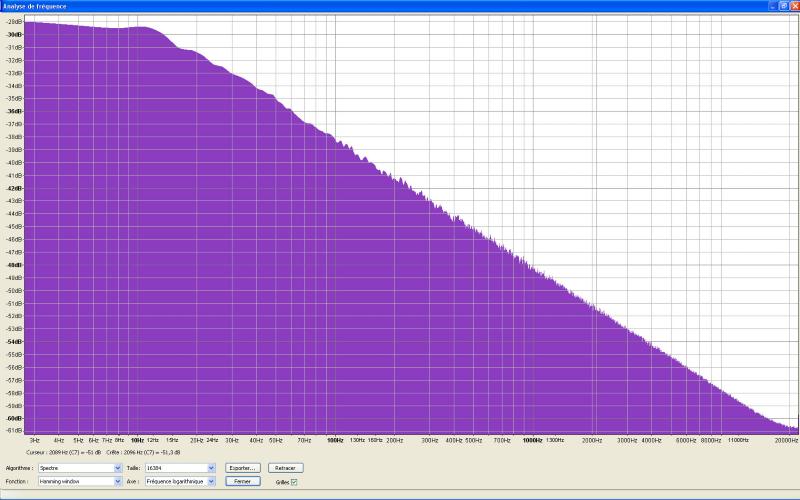
Remarques :
- ces deux graphiques révčlent ŕ
la fois : 1. la qualité de ces bruits générés
par Audacity qui sont conformes aux définitions, 2. la précision
de l’analyseur de spectre ; il est important d’ętre sűr de
la qualité de ces outils tant il est vrai que toute imprécision
se traduirait par des corrections inappropriées ;
- analyser un échantillon d’une durée
d’une minute suffit ŕ révéler avec une bonne précision
la qualité d’un spectre de bruit, et deux minutes conviennent pour atteindre
la précision maximale (c’est-ŕ-dire que rallonger la durée
n’apporte pas d’information supplémentaire).
CD de test
J’ai réalisé un CD comprenant divers
échantillons de bruits tests. Ils ont été créés
avec le générateur de bruit d’Audacity réglé sur
un niveau de 0.6 et une durée de 6 minutes.
1. bruit rose gauche
2. bruit rose droit
3. bruit rose stéréo (G≠D)
4. bruit rose mono deux canaux (G=D)
5. bruit blanc gauche
6. bruit blanc droit
7. bruit blanc stéréo (G≠D)
8. bruit blanc mono deux canaux (G=D)
Les plages 1, 2, 5, 6 servent ŕ tester
séparément les voies de droite et de gauche afin de mettre en
évidence d’éventuelles asymétries. Si elles sont importantes,
alors il faut configurer le DEQ en dual mono et corriger chaque voie
séparément.
Sinon on se contentera d’une correction globale en
mode stereo link avec les séquences 3 et 7, voire 4 et 8.
Quelle différence entre un bruit stéréo
et un bruit mono deux canaux ? Dans le premier cas les deux canaux diffusent
un signal de bruit différent, tandis que dans le second c’est le męme
signal qui est émis ŕ droite et ŕ gauche. Ŕ quoi
ça sert un bruit mono deux canaux ? Je ne suis pas sűr encore,
peut-ętre ŕ mettre en évidence certains petites asymétries
via des phénomčnes d’interférences ? Disons que c’est
lŕ ŕ ma disposition mais que je compte surtout utiliser les séquences
3 et 7.
traitement des différents registres
grave
Lorsqu’il y a des résonances dans la pičce
et qu’on rčgle un caisson de basses ŕ l’oreille, voici en général
ce qui se passe :
1. on rčgle le volume du caisson sur ces
résonances pour qu’elles restent ŕ un niveau tolérable ;
2. mais comme ces fréquences sont amplifiées
par la salle plusieurs dizaines voire centaines de fois, on se retrouve avec
des trous énormes ŕ côté ;
3. on essaie de compenser le manque de graves
en relevant la fréquence de coupure ;
4. d’oů un recouvrement trčs imparfait
avec les enceintes principales.
Pour un bon raccord entre le caisson et les enceintes,
il faut plutôt abaisser la fréquence de coupure et rehausser le
volume, mais ce n’est possible qu’en ayant au préalable atténué
les résonances. Voici une procédure pour réaliser tout
ceci :
1. utiliser comme signal test un bruit rose et
analyser le spectre en affichage logarithmique pour repérer les fréquences
de résonance ;
2. réduire trčs précisément
et drastiquement ces résonances au paramétrique, remonter le volume
du caisson, abaisser la fréquence de coupure ;
3. recommencer autant de fois qu’il faut en jouant
de tous les paramčtres disponibles (filtres paramétriques, filtres
graphiques, gain du caisson, fréquence de coupure du caisson) pour linéariser
autant que faire se peut la réponse du grave.
Remarque :
Les caissons Rel présentent la particularité
de prélever leur signal sur les sorties enceintes de l’ampli (évidemment
de telle maničre ŕ ne pas perturber le courant qui alimente les
enceintes principales). Par rapport ŕ une prise de signal sur la sortie
de niveau ligne de l’ampli (tape out) cela a pour avantages : de ne pas
avoir ŕ rerégler le volume du caisson chaque fois qu’on touche
ŕ celui de l’ampli, et de donner au grave extręme une coloration
similaire au grave diffusé par les enceintes principales. Dans ces conditions,
pour rehausser le volume de l’extręme grave, c’est-ŕ-dire en dessous
de la fréquence limite basse des enceintes principales (60Hz dans mon
cas), il est de beaucoup préférable d’agir directement sur le
volume du caisson plutôt qu’augmenter les graves ŕ l’égaliseur,
avec pour conséquence un risque de surcharge de l’ampli principal.
médium
Dans la foulée, le męme signal test est
utilisé pour corriger les résonances éventuellement présentes
dans le médium ainsi que d’autres accidents. Ces derniers se corrigent
en général trčs bien ŕ l’égaliseur graphique.
aigu
La réponse ŕ un bruit blanc présentée
en affichage linéaire permet simultanément de visualiser les accidents
de l’aigu et de viser une courbe cible.
réglages globaux du DEQ2496
menus I/O et utility
I/O page1 > select input > main in
I/O page1 > samplerate > 96kHz
I/O page2 > select AUX/DIG out > main out
I/O page2 > dither > 24 bits
I/O page2 > B noise shaper
I/O page3 > select RTA input > main out
utility 1 > channel mode > selon comparaison
des réponses ŕ droite et ŕ gauche
utility 1 > GEQ mode > true response
utility 1 > gain offset > voir paragraphe suivant
utility 1 > RTA noise correction > off
utility 1 > RTA/mic input > mic level +15V
utility 1 > RTA/mic mic level > -40dBv/Pa (pour
le micro B5 avec sa capsule ominidirectionnelle)
utility 2 > MIDI > off
problčme de gain
Le seul fait d’intercaler un DEQ2496 entre le lecteur CD et l’ampli (le tout en analogique ici), de l’allumer et le mettre
en bypass fait perdre environ 6dB ! D’aprčs Simon Ashton, cela vient
du fait que l’appareil a la particularité de supporter des niveaux d’entrées
analogiques trčs élevés avant de saturer. Je ne sais pourquoi
cela a pour conséquence une diminution du niveau du signal ŕ la
sortie, mais voilŕ, c’est un fait.
Il y a deux façons de compenser :
1. avec le bouton de volume de l’ampli
Le problčme est que 6dB représentent
tout de męme une multiplication par 4 de la puissance. Ce n’est pas négligeable
pour un ampli qui n’est pas des plus puissants (2x50W seulement mais compensé
par un bon rendement des enceintes) et qui a un bruit de fond assez élevé.
2. au niveau du DEQ avec utility 1 > gain
offset > +6dB
Cette augmentation étant numérique,
le risque cette fois est de saturation numérique (digital clipping).
Risque évidemment diminué si le GEQ et le PEQ sont utilisés
principalement en réduction.
Suggestions pour commencer :
- gain offset +4dB avec un programme qui réduit
fortement les graves sur le DEQ (pour mieux les augmenter au niveau du caisson
comme expliqué ci-dessus).
Pour voir si cela convient, écouter
pendant quelques temps avec la fonction METER branchée sur output et
lire ŕ la fin le niveau maximal atteint (peak). Il y a aussi une diode
de clip mais on n’a pas le regard toujours braqué dessus !
ŕ propos de DynEQ
Le DEQ2496 comprend en plus 3 filtres dynamiques
conçus pour rehausser ou abaisser le niveau sur une certaine bande de
fréquence en fonction du niveau général du signal. Tous
ces paramčtres étant bien sűr ŕ spécifier
pour chaque filtre.
La premičre idée qui vient ŕ
l’esprit est de s’en servir en tant que correcteur automatique de loudness.
En fait ça ne peut pas marcher car il faudrait que le réglage
du volume d’écoute se fasse en amont du DEQ. Voici ce qui va se passer
si on essaie quand męme de programmer un filtre pour rehausser les graves
lorsque le niveau global du signal tombe en dessous d’un certain seuil :
au dessus de ce seuil, les graves ne seront pas augmentés et ne seront
donc pas entendus puisque l’écoute se faible ŕ faible volume !
et on risque de se remettre ŕ les entendre en-dehors de ces passages
forte !
En revanche il y a une logique ŕ employer le
DynEQ pour corriger la dureté du son dans la zone de sensibilité
maximale de l’oreille. Il est évident en effet que plus le niveau du
signal source est élevé, plus la présence de fréquences
dans cette zone est irritante. La difficulté est de régler le
seuil ŕ partir duquel déclencher ce filtre sachant que tous les
enregistrements sont différents. Quelques tests suggčrent qu’un
seuil de -25dB devrait convenir. On pourra ensuite peaufiner. Par exemple en
écoutant quelques temps avec l’afficheur sur DynEQ sur lequel sont visualisés
le franchissement du seuil et l’ampleur de la correction.
configuration
mon systčme
- lecteur CD Yba special disposant
uniquement d’une sortie analogique
- égaliseur Behringer DEQ2496 avec alimentation,
module d’entrée analogique et module de sortie analogique modifiés
par Simon Ashton / Audiosmile
- ampli intégré John Shearne Phase2
- enceintes BC-Acoustique Araxe premičre
génération (rendement 92dB, bande passante 60Hz-20kHz ŕ
+/-3dB)
- caisson Rel Quake (descendant ŕ 23Hz
-6dB)
mon salon de musique
Il présente une géométrie
trčs défavorable de double cube : longueur = 4.97m , largeur
= 2.47 , hauteur = 2.53 , soit pratiquement 5x2.5x2.5. En théorie, les
principales fréquences critiques se situent autour de 34, 68, 100 et
136 Hz.
La pičce étant petite, il y a trčs
peu de marge de manœuvre sur le placement des différents éléments.
Et pas davantage sur le point d’écoute, situé ŕ une hauteur
de 0.95m et une distance de 2.8m des tweeters de chaque enceintes.
réglages de la chaîne d’analyse
micro
Un Behringer B-5 muni de sa capsule omnidirectionnelle
(il possčde également une capsule cardioďde interchangeable)
est utilisé comme micro de mesures. Il possčde une courbe de réponse
trčs plate sur tout le spectre. Mais il nécessite tout de męme
quelques corrections (explications dans appareils_musiques_ea.pdf) :
- dans l’aigu :
|
bande |
6.3k |
8k |
10k |
12.5k |
16k |
20k |
|
correction |
-1 |
-1 |
-1 |
0 |
+3 |
+5 |
- dans le grave :
|
bande |
20Hz |
25 |
31.5 |
40 |
|
correction |
+3 |
+2 |
+1 |
0 |
attention : vérifier que le filtre low cut n’est pas activé
position
Le micro est placé au point d’écoute,
dirigé vers les tweeters.
autres appareils
RC50 : fantom power on et sélectionner
un patch avec input out sur main
DEQ1024 : low cut off et high
cut off, égaliseur graphique avec courbe
de correction micro ci-dessus
réglage des niveaux
ampli : 9h30 sans le DEQ2496
10h avec le DEQ2496 et gain offset +3dB
RC50 : mic level max et master
level max
DEQ1024 : gain 0
Audacity : niveau d’enregistrement max
remarques :
- ne pas pousser davantage l’ampli, surtout pour
la diffusion de bruits roses qui ont un trčs fort contenu en graves ;
- mettre des bouchons d’oreille car ça
peut durer longtemps, c’est pas agréable d’écouter du bruit, et
ça peut ętre fort (j’ai mesuré 80dB SPL sur bruit blanc
au point d’écoute, dont je m’éloigne évidemment lors des
enregistrements des séquences tests).
analyse au bruit rose
Réponses au bruit rose avant correction, successivement voie de droite seule, voie de gauche seule, et stéréo :
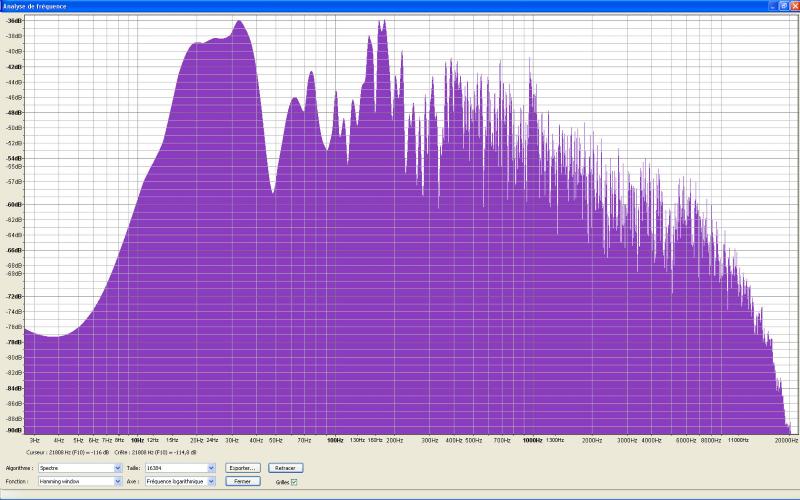
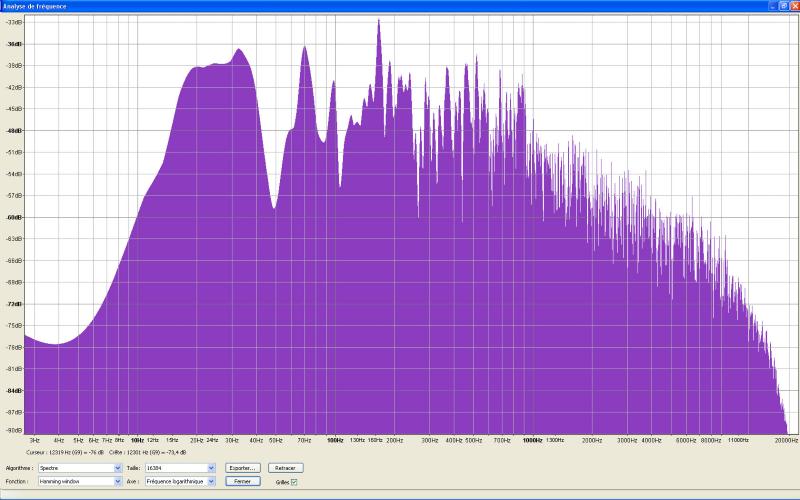
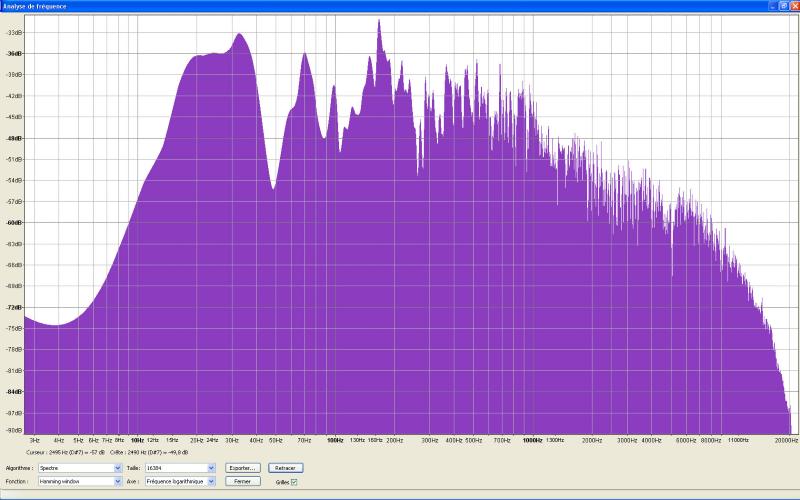
Premičres conclusions :
- on observe bien quelques asymétries,
mais elles me semblent assez faibles pour autoriser des corrections en mode
stereo link ;
- les problčmes dans le grave sont flagrants
et réclament des mesures de corrections importantes ; notons en
particulier le trou de plus de 20dB entre les deux premičres résonances.
corrections grave et médium
Résultat aprčs corrections :
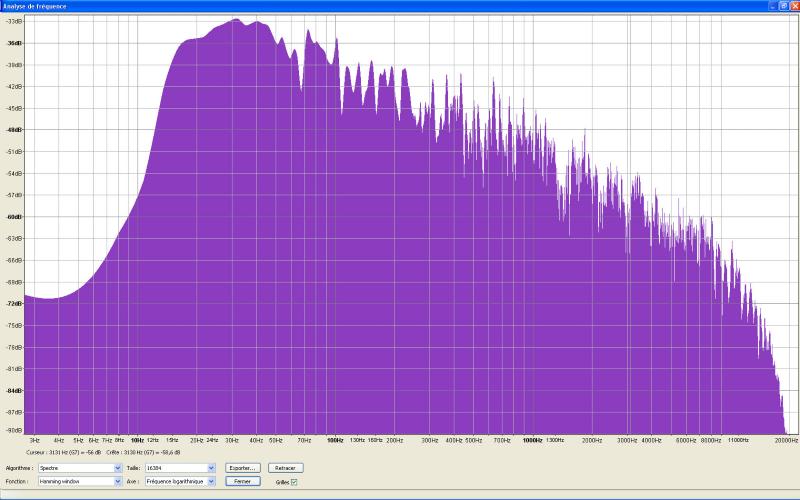
Les corrections consistent en ceci :
caisson de basses : volume 2 heures (contre 9h avant) et fréquence de coupure 10h30 (contre 12h avant)
PEQ : les 10 filtres disponibles sont utilisés
|
fréquence |
BW/oct |
gain |
|
|
1 |
22.2 |
L12dB |
-15 |
|
2 |
34.8 |
1/2 |
-12 |
|
3 |
29.9 |
3/4 |
-4 |
|
4 |
76.9 |
1/5 |
-15 |
|
5 |
99.1 |
1/7 |
-10 |
|
6 |
54.5 |
1/9 |
+9 |
|
7 |
120 |
1/10 |
+6 |
|
8 |
166 |
1/10 |
-4.5 |
|
9 |
240 |
1/10 |
-7 |
|
10 |
190 |
1/10 |
-4.5 |
GEQ, dans le grave
|
20Hz |
25 |
31.5 |
40 |
|
-6 |
-3 |
-1 |
-4 |
GEQ, dans le médium
|
800Hz |
1000 |
1250 |
1600 |
2000 |
2500 |
3150 |
|
-2 |
-5 |
-2 |
-3 |
-2 |
-1.5 |
-1 |
Remarques :
- étant donné que la baisse du
grave est trčs importante, compensée par une forte remontée
du volume du caisson, surtout ne pas bypasser le PEQ ;
- la linéarisation du grave n’est parfaitement
valable qu’au point d’écoute ; mais la baisse drastique des résonances
s’entend de partout, ŕ ceci prčs :
Comme je viens de le dire, tout
ceci vaut pour le point d’écoute. Que se passe-t-il ailleurs ? Il est
recommandé de vérifier que certaines fréquences ne sont pas
surcorrigées pour le point d’écoute, avec pour contrepartie des gros
boum-boum en d’autres points de la pičce et des excursions dangereuses
des haut-parleurs de grave.
La meilleure méthode pour ce faire est de recourir ŕ des fréquences de
balayage en se déplaçant dans la pičce et en observant le mouvement des
haut-parleurs.
De fait, il apparaît clairement que les 9dB de gain ŕ 54.5Hz (6e filtre
du PEQ) sont exagérés : ŕ fort volume, les mouvements du haut-parleur
du caisson de basse sont impressionnants, et en certains points de la
pičce des ronflements épouvantables se font entendre. Une correction
aussi importante provient probablement du fait que le point d’écoute
doit ętre proche d’un nœud d’onde autour de cette fréquence. Quelques
essais montrent qu’une correction de +3dB constitue un compromis
acceptable entre une sensation au point d’écoute proche de la linéarité
dans les graves, et une forte atténuation des ronflements ailleurs.
analyse au bruit blanc
Je n’ai hélas pas gardé l’enregistrement du bruit blanc stéréo au point d’écoute, c’est-ŕ-dire ŕ 2.8m, qui a servi ŕ faire les corrections. Ŕ un détail prčs que l’on verra plus loin, la réponse suivante avant corrections enregistrée ŕ une distance de 2.5m et affichée en mode linéaire montre la męme tendance :
On remarque que la tendance générale
est nettement ŕ la baisse : environ 1dB par octave entre 20 et 10.000Hz.
Autrement dit, la réponse naturelle de la pičce correspond déjŕ
ŕ une bonne courbe cible.
Ensuite la chute s’accélčre : 9dB
de 10 ŕ 16kHz puis encore 9dB de 16 ŕ 20kHz, soit 18dB sur la
derničre octave.
On peut se demander si cette baisse brutale
dans l’extręme aigu est bien réelle ou s’il ne s’agirait pas plutôt
d’une sous-compensation du micro qui a une baisse de sensibilité dans
ce registre. Étant donnés :
1. que le micro est déjŕ un peu
compensé,
2. que la baisse observée est vraiment
trčs importante,
3. que des mesures effectuées ŕ
différentes distances (successivement 2.3m, 2.5m, et 2.8m) montrent une
baisse un soupçon moindre ŕ mesure qu’on se rapproche de la source,
je pense que le phénomčne est bien réel
et demande compensation.
Toutefois, il n’est pas utile de surcorriger, considérant que mon oreille n’entend plus grand chose au-delŕ de 16kHz, et que le peu qu’il y a ŕ entendre ne semble pas d’une grande qualité. Donc je me contenterai de ceci :
|
12.5k |
16k |
20k |
|
+1 |
+1 |
inchangé |
Résultat aprčs correction au point d’écoute :
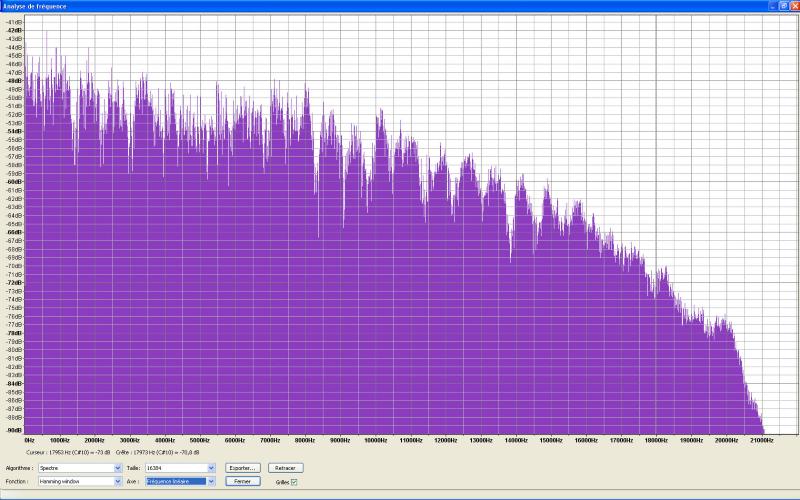
On remarque une chose qui n’apparaissait
pas sur le graphique précédent : une succession réguličre
de creux et de bosses. On appelle ça un filtre en peigne pour des raisons
que l’on comprend aisément. Le phénomčne est dű ŕ
des interférences entre les ondes qui arrivent directement en provenance
des enceintes et celles qui sont réfléchies par les parois (c’est
pourquoi il est encore plus accentué sur le test avec bruit blanc mono
deux canaux). Précisément dans ce cas, il s’agit trčs probablement
de réflexions sur le mur du fond (derričre le point d’écoute
donc) puisque le filtre en peigne n’apparaît pas sur les mesures effectuées
ŕ une distance des enceintes de 2.5m mais qu’il est lŕ au point
d’écoute situé 30cm plus loin. Or en s’éloignant des enceintes,
on se rapproche du mur du fond, et comme la pičce est petite, la distance
entre le point d’écoute et ledit mur se réduit ŕ 1.4m.
Une distance minimale de 2m est généralement recommandée,
mais je n’ai pas le choix, je ne peux pas avancer mon fauteuil ŕ cause
de tout l’équipement placé devant qui sert ŕ faire de la
musique électroacoustique.
La vraie question est : est-ce gęnant ?
Pour tout dire je ne me suis jamais rendu compte de rien ŕ l’écoute,
et ce n’est qu’en comparant les deux graphiques précédents que
j’ai découvert l’existence de ce filtre en peigne. Si un tel filtrage
en peigne passe généralement inaperçu, c’est ŕ cause
d’un phénomčne psychoacoustique appelé effet Haas ou effet
de précédence.
Le premier son qui arrive ŕ l’oreille sert
ŕ déterminer la direction de la source. Le cerveau élimine
de lui-męme tout signal semblable qui arrive dans un délai de 30
ŕ 40 millisecondes. Ŕ 340m/s, le son met environ 3ms pour parcourir
1m, donc 30ms correspondent ŕ 10m. Dans une pičce d’écoute
moyenne, c’est largement plus que la différence de distance parcourue
entre un son direct et un son réfléchi. Car au-delŕ de
30 ŕ 40ms, le phénomčne de masquage temporel disparaît
et le son retardé commence ŕ ętre entendu comme un écho
distinct. Ajoutons encore que le masquage persiste en dessous de ce seuil temporel
męme si le niveau du son retardé est de 6 ŕ 10dB supérieur
au niveau du son direct.
Conclusion : les interférences entre son
direct et son réfléchi qui créent un tel filtre en peigne
ont assez peu d’effets sur la qualité du son, en particulier la précision
de localisation des sources. J’en resterai donc lŕ pour ce qui est des
corrections acoustiques.
corrections psychoacoustiques
dans la zone de sensibilité maximale de l’oreille
Les explications ayant été
données plus haut, voici directement les paramčtres que j’applique
au premier filtre du DynEQ :
M-gain : -6dB
threshold : -25dB
ratio : 1/10
attack : 0 (minimum)
release : 20ms (minimum)
mode : BandPass
frequency : 3169
BW : 1
Remarque : -6dB peut sembler une baisse importante,
mais d’une part, le filtre étant dynamique, il s’agit d’une baisse maximale
qui n’est appliquée que sur les sons les plus forts, d’autre part, si
cela correspond ŕ une diminution de puissance d’un facteur 4 (ce qui
est bien pour les oreilles sensibles), la sensation d’intensité sonore
quant ŕ elle n’est diminuée que d’un tiers.
en fonction du niveau d’écoute
Pour effectuer une telle correction, il
faut au préalable avoir une idée du niveau d’écoute. La
fonction METER du DEQ2496 permet une telle mesure, il suffit de brancher un
micro et de préciser sa sensibilité (-40dBV/Pa pour le B5 muni
de sa capsule omnidirectionnelle). Voici les résultats pour divers échantillons
de musiques écoutés ŕ différents niveaux, et comment
je les entends :
- entre 80 et 90 dB SPL, c’est une sensation
de son fort ;
- entre 75 et 85 dB SPL, c’est un niveau
moyen, confortable ;
- entre 70 et 75 dB SPL, cela sonne doux.
Cela suggčrerait de créer trois programmes :
fort, moyen et doux. C’est possible mais je trouve ça un peu difficile
ŕ gérer, c’est-ŕ-dire qu’il faut ŕ chaque fois réfléchir
avant d’écouter un disque au programme ŕ charger. Je préfčre
avoir un programme normal qui sert dans la majorité des cas, et
un programme loudness réservé ŕ l’écoute
ŕ bas volume. Celui-ci reprend tous les réglages précédents,
sauf :
1. utility > gain offset 0 (au lieu de +3)
2. DynEQ > M-gain -3 (au lieu de -6)
3. GEQ : un filtre low shelf de +3dB
ŕ 315Hz pour rehausser le grave de +3dB ŕ 25Hz ŕ 0 ŕ
315Hz
4. GEQ : un filtre high shelf de
+7dB ŕ 5kHz pour avoir une augmentation linéaire de l’aigu de
0 ŕ 5kHz ŕ +4dB ŕ 20kHz
remarque : je ne comprends pas trop les réglages
ŕ effectuer sur ces filtres pour obtenir les résultats voulus…
En tenant compte de toutes les corrections, voici ce que cela donne pour le paramétrage du GEQ (1 normal, 2 loudness) :
|
20 |
25 |
31.5 |
40 |
50 |
63 |
80 |
100 |
125 |
160 |
200 |
250 |
315 |
400 |
500 |
|
|
1 |
-6 |
-3 |
-1 |
-4 |
|||||||||||
|
2 |
-2.5 |
0 |
+2 |
-1.5 |
+2 |
+2 |
+1.5 |
+1.5 |
+1 |
+0.5 |
+0.5 |
|
630 |
800 |
1k |
1.25 |
1.6 |
2 |
2.5 |
3.15 |
4 |
5 |
6.3 |
8 |
10 |
12.5 |
16 |
20 |
|
-2 |
-5 |
-2 |
-3 |
-2 |
-1.5 |
-1 |
+1 |
+1 |
|||||||
|
-2 |
-5 |
-2 |
-3 |
-2 |
-1.5 |
-1 |
+0.5 |
+1 |
+2 |
+3.5 |
+4.5 |
+4 |
correction supplémentaire
Je l’ai dit, ma pičce d’écoute
est petite et je suis obligé de me tenir plus éloigné des
enceintes qu’il ne faudrait : le point d’écoute est ŕ 2.8m
tandis que les enceintes sont espacées de 1.4m, ce qui fait un angle
d’ouverture de 30° seulement. On préconise en général 60°
pour une séparation stéréophonique idéale, et on
peut descendre ŕ 45° si l’on veut privilégier l’écoute
des sources centrales. Mais 30°, cela fait vraiment une scčne sonore
étriquée.
Le DEQ2496 a la solution, une fonction qui s’appelle
WIDTH. Elle ne fonctionne qu’en mode stereo link et pas en dual mono,
d’oů mon insistance pour travailler dans ce mode. Elle permet de régler
la largeur de la scčne sonore (et aussi de corriger des asymétries,
mais ces derniers paramčtres ne me sont pas utiles). Donc je me contente
du seul paramčtre stereowidth que je mets sur +2.
Mon salon de musique n’a pas
changé mais deux nouveaux éléments sont venus s’ajouter ŕ mon
installation : un disque dur et une interface Teac WAP2200 (http://www.teac.eu/fr/hifi-audio/wap-audio-streaming/system/wap-2200/). C’est que, entre-temps, j’ai numérisé toute ma cd-thčque. Pour ça je me suis servi du logiciel Exact Audio Copy (http://www.exactaudiocopy.de/)
qui garantit, sauf CD trčs abîmé, un fichier conforme ŕ l’original.
Toute ma musique est donc maintenant sur un disque dur externe, soit
plus de 200 gigaoctets en format non compressé wav. Pour l’écouter
directement sur ma chaîne, il suffit d’intercaler un boîtier comme le
wap de Teac (Logitec fait également un trčs bon produit, la
squeezebox…).
Le salon de musique n’ayant pas
changé, il n’y a rien ŕ toucher aux réglages d’égalisation, seulement ŕ
la configuration de l’entrée et au gain.
Pour régler l’entrée, c’est facile : I/O page1 > select input >
digital optical puisque le wap dispose d’une sortie numérique optique
qui permet de rentrer directement en numérique dans le deq.
Pour régler gain offset (dans le menu utility, page 1), c’est un peu plus compliqué.
Pour commencer, il m’a fallu comparer les niveaux ŕ l’entrée du deq
(meter>source input) en passant des séquences identiques
alternativement avec le lecteur CD et le wap. Il apparaît qu’il y a 7.5
ŕ 8dB de plus en numérique qu’en analogique (cela dépend de la séquence
et de la mesure selon qu’elle est rms ou peak).
Il convient d’autre part d’avoir ŕ l’esprit que les modules GEQ, PEQ et
DEQ travaillent essentiellement ŕ la baisse, hormis deux filtres du PEQ
: +9dB ŕ 54.5Hz sur 1/9 d’octave, et +7dB ŕ 120Hz sur 1/10 d’octave.
L’étroitesse de ces filtres suggčre qu’on devrait obtenir ŕ peu prčs le
męme niveau de sortie qu’ŕ l’entrée en réglant gain offset sur 0dB (au
lieu de +3 avec le lecteur CD). C’est vrai en général, mais de la
saturation risque tout de męme de se produire. Vérification faite sur
eruption de Van Halen qui frôle en entrée un niveau de 0dB peak, ça
clippe effectivement en sortie. Donc au final il est plus prudent de
régler gain offset sur -3dB. Je verrai ŕ l’usage si ça convient bien…